
Попробуем перенести данные на сторону клиента, избавившись тем самым от части запросов на backend и сократив затраты на передачу данных.
1. Язык демо-примеров
TypeScript.
2. Какие данные переносим?
Под квазипостоянными данными будем подразумевать все данные, которые либо не меняются вовсе, либо меняются с большой периодичностью. Например, такими могут оказаться справочники, системные настройки и т.д. В нашей конкретной задаче будем переносить дерево объектов и связанные с ним версии. Действительно, существует не так много триггеров, способных повлиять на дерево объектов. Это, как правило, ввод в эксплуатацию (вывод из эксплуатации) нового оборудования, изменение группировок оборудования (когда эффективных организаторов меняют ещё более эффективные, запуская при этом процессы реорганизации), в конце концов, не исключено, что станет больше не только оборудования, но и территорий, на котором оно расположено.
3. Мотивация
Результатом переноса дерева должны стать следующие преимущества:
- Снижение нагрузки на БД. Дерево объектов – ресурс, необходимый для любого расчета. Кроме того, версия дерева на дату – постоянный элемент для отображения на frontend-е.
- Снижение затрат на синхронизацию доступа. Пункт, который непосредственно вытекает из предыдущего. Дерево объектов слишком популярный ресурс, за который придётся бороться слишком большому количеству желающих. Да, в режиме readonly, но всё равно это дополнительные затраты и потенциальные проблемы, связанных с конкурентным доступом. Пусть и весьма маловероятные.
- Снижение затрат на транспорт. Постоянно передавать несколько тысяч объектов в дереве с сервера на клиент – ощутимые расходы.
- Упрощение структуры хранения. Не самый очевидный пункт. Если существует серверная БД, которая является мастером и всецело следит за безопасностью (обеспечивает ссылочную целостность, например), то для расчетов хотелось бы избавиться от лишних проверок, констрейнтов, и т.п. для более быстрой работы с данными.
4. Обзор браузерных хранилищ
Что нам может предложить браузер для хранения данных?
- Cookie. Отправляются с каждым запросом и точно не заточены для подобного объёма данных.
- LocalStorage. Также скорее небольшое хранилище для пар ключ-значение. Синхронный API, который может блокировать основной процесс JavaScript.
- WebSQL. Так и не стал стандартом и устарел (w3c прекратил работу над спецификацией в 2010).
- API File System. Поддерживается, мягко говоря, не всеми браузерами.

Рис. 1
- Indexed DB. Широко поддерживаемая, индексируемая, версионируемая база данных типа «ключ-значение». Позволяет хранить значительно больше данных, нежели localStorage. Кроме того, IndexedDB в JavaScript работает асинхронно, что позволяет не блокировать основной поток. Обработка даже большого объёма данных не приведёт к «зависанию» при отрисовке пользовательского интерфейса.
Итак, выбор в пользу IndexedDB очевиден. Кроме основных преимуществ в виде асинхронной работы, большого объёма, стабильности и широкого применения, есть и функционал, который напрямую подходит под нашу задачу, – встроенное версионирование. Как только на сервере появится новая версия дерева, открытие клиентской БД будет требовать синхронизировать данные. Немаловажным аспектом является и то, что IndexedDB поддерживает транзакции для надёжности (это является и причиной медленной работы indexedDb в некоторых сценариях работы, но это обсудим чуть позже).
5. Применимость IndexedDB
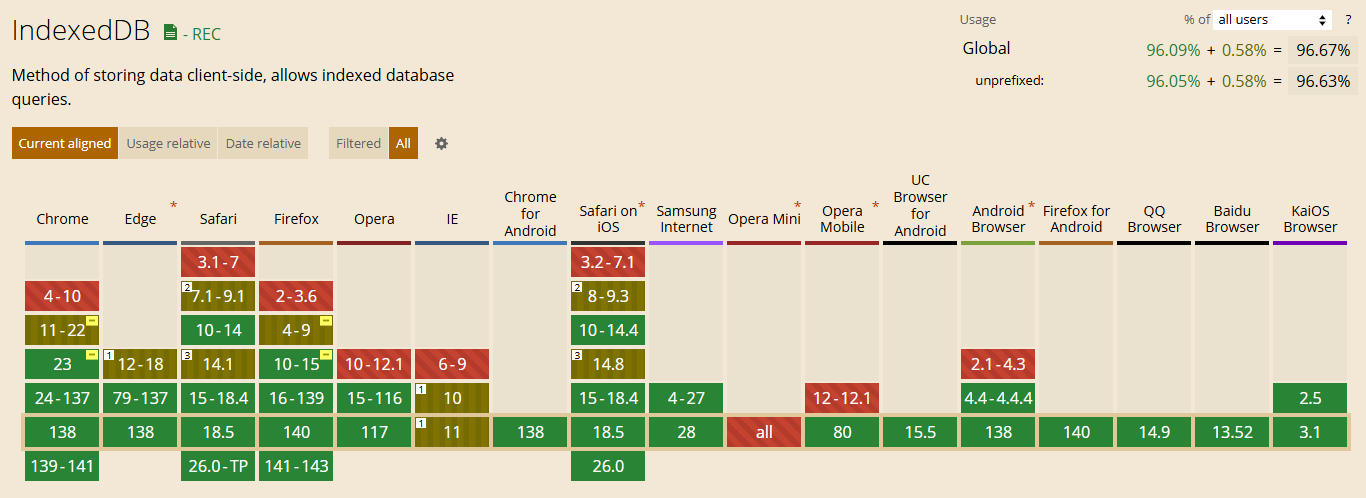
Рис. 2
Согласно caniuse, IndexedDB поддерживается практически всеми современными (и не очень) браузерами. Есть некоторые различия по доступности разного функционала, квотам и максимальному объёму в зависимости от браузера, но для конкретной задачи это не принципиально. Мы проверяем на Chrome версии 138.0.7.1586. Максимальный объём
У IndexedDB есть различные ограничения по размеру в зависимости от браузера, дискового пространства и пользовательских настроек. Размер локальных данных ограничен квотами. Все современные браузеры контролируют дисковое пространство, чтобы защитить пользовательские ресурсы. Нельзя, или почти нельзя, безнаказанно засорять дисковое пространство :) Это достигается с помощью политик управления квотами, которые могут отличаться в разных браузерах. Некоторые браузеры (на основе Chromium) используют заданный процент от общего дискового пространства, другие же используют фиксированное максимальное ограничение для каждого источника (Firefox). Chrome (как и браузеры на основе Chromium) могут использовать до 80% свободного места на диске, используют общий пул и могут потребовать частичного или расширенного одобрения со стороны пользователя на использование квоты. Firefox выделяет около 2 Гб для настольных компьютеров и около 5 Мб для мобильных устройств. Устройства iOS ограничивают квоты сильнее – около 1 Гб на источник. Исторически эти цифры менялись (например, в старых версиях Firefox выделялось 50 Мб на десктопных ПК), но развитие браузеров, как правило, смягчают квоты.
Когда приложение превышает выделенную квоту, большинство браузеров выдают исключение QuotaExceededError при попытке сохранить данные. Типичный подход – заключить операции записи в блоки try/catch с последующим сокращением неиспользуемых данных. Однако в нашем конкретном случае данные ограничения выглядят излишними. В нашей задаче нет необходимости размещать в IndexedDB большие медиафайлы (а в том числе на это IndexedDB и рассчитана), мы храним только несколько тысяч объектов и несколько версий. В такой ситуации можно столкнуться с нехваткой памяти в JavaScript до того, как сама IndexedDB переполнит квоту.
Ещё один немаловажный факт – это время хранения данных. Как правило, данные IndexedDB хранятся неограниченно долго, пока пользователь сам не очистит данные браузера. Но некоторые браузеры (например, Safari) могут удалить большие кэши сайтов, неиспользуемые в течение длительного времени, если потребовалось место. Но, даже если данные из IndexedDB были удалены, любая попытка прочитать данные приведёт к синхронизации.
7. Проблемы использования IndexedDB
Не бывает ультимативного инструмента для решения всех задач, и IndexedDB, как и любой другой инструмент, имеет ряд недостатков. Попробуем озвучить некоторые из них и посмотреть, насколько они критичны в контексте нашей задачи.
- Медленные транзакции. IndexedDB поддерживает транзакционность. Причём есть как readonly, так и readwrite (есть ещё versionChange, но это автоматический тип, выставляемый при смене версии) транзакции. Несколько readonly транзакций могут одновременно работать с одним хранилищем, а readwrite – нет. Транзакции readwrite блокируют хранилище и каждая следующая такая транзакция должна дождаться выполнения предыдущей. Воспользуемся чужими цифрами. Приведены цифры вставки 10000 записей в одной транзакции и случая 1 запись = 1 транзакция (пример). Разница в 50+ раз впечатляет! Однако для нашего примера это неактуально. Нам необходимо один раз получить дерево объектов и имеющиеся версии и записать их в рамках одной транзакции. Далее остается только добавлять изменения при появлении новой версии дерева (что, согласно бизнес-процессу, происходит не так уж и часто). Вся основная работа построена вокруг чтения хранилища объектов дерева и версий.
- Оптимизация IndexedDB направлена на скорость чтения. Пункт, связанный с предыдущим. Да, оптимизация записи не является первоочередной задачей для разработчиков Chromium, как следует из ответа по ссылке, а все усилия сосредоточены на оптимизации чтения. Но это как раз то, что мы будем активно использовать.
- Проблема параллельного обновления. Транзакции обсудили, обсудим ещё одну возможность IndexedDB – версионирование. Предположим:
- Пользователь открыл приложение во вкладке браузера с версией БД 1.
- На сервере обновляется версия дерева.
- Тот же пользователь открывает приложение в другой вкладке.
Теперь есть одна вкладка с версией 1 и вторая, в которой срабатывает событие upgradeneeded. Проблема в том, что БД привязана к домену (источнику) и, как следствие, одна на обе вкладки. И она, в отличии от кота Шрёдингера, не может одновременно быть в состоянии суперпозиции (быть и версией 1, и 2). Чтобы обновить до версии 2, все соединения к версии 1 должны быть закрыты. Чтобы это организовать, можно прослушивать событие versionchange на объекте базы, и закрыть соединение к БД при его срабатывании.

Рис. 3
- Автоматическая фиксация транзакций. Ещё одна фича indexedDB. Сейчас у транзакции есть метод commit (и утверждается, что он незначительно, но увеличивает производительность), но indexedDB завершает транзакции автоматически и без него. На основании чего это происходит? Когда очередь микрозадач пуста (все запросы завершены), тогда транзакция завершится автоматически. Такой автокоммит имеет побочный эффект – не получится вставить асинхронную операцию, которая станет макрозадачей (fetch или setTimeout) в середину транзакции. IndexedDB не будет ждать их выполнения. Транзакция завершится раньше, чем браузер приступит к выполнению макрозадач. Отчасти это тоже следствие особенностей readwrite транзакций. Они блокируют хранилище и поэтому должны завершаться быстро. Решается данная проблема разделением транзакций IndexedDB и других асинхронных операций.
- Ограничения на данные, которые можно сохранить. IndexedDB использует стандартный алгоритм сериализации для хранения и копирования объектов, поэтому хранимые объекты должны быть сериализуемы. Например, не удастся сохранить объекты с циклическими ссылками. В нашей задаче циклические ссылки – явная проблема с деревом, и до сохранения в клиентское хранилище дело не дойдёт. По сути, данные уже прошли одну сериализацию при отправке с backend-a. Все проверки оставляем на стороне серверной БД, считая, что если в серверной БД нет ошибок, то и в клиентской их быть не должно
Как видно, IndexedDB не лишена недостатков и иногда может оказаться медленнее иных способов хранения, но все они либо решаемы, либо целиком лежат за рамками поставленной задачи, поэтому поговорим немного о терминах IndexedDB и перейдём к реализации.
8. IndexedDB: описание и используемые термины
IndexedDB – это NoSQL система хранения, позволяющая хранить практически что угодно в браузере пользователя. Поддерживает транзакции и индексы и хорошо подходит для хранения большого объёма структурированных данных. Каждая база данных уникальна для источника (домена/поддомена) и к ней не могут получить доступ ни один другой источник.
Термины, которые будут использованы далее:
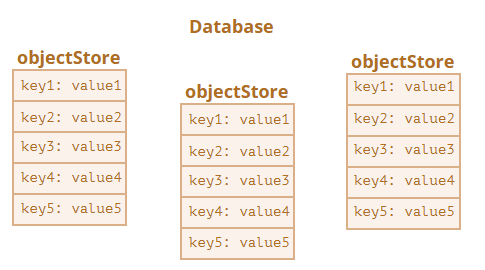
Рис. 4
- База данных (database) – самый высокий уровень IndexedDB. Содержит хранилища объектов.
- Хранилище объектов (objectStore) – отдельный сегмент для хранения данных, аналогичный таблицам в реляционных БД.
- Индекс (index) – «расширение» к хранилищу, которое отслеживает данное поле объекта. Для каждого значения этого поля хранится список ключей объектов, которые имеют это значение.
- Операция (operation) – взаимодействие с БД.
- Транзакция (transaction) – оболочка операции или группы операций, обеспечивающая целостность БД. Все операции чтения или записи в IndexedDB должны быть частью транзакции. Это позволяет выполнять операции без риска конфликтов с другими потоками.
- Курсор (cursor) – механизм перебора записей. Использовать не будем, так как появившиеся функции getAll быстрее загружают данные в память, а необходимости экономить память за счет поэлементной догрузки у нас нет.
9. Реализация
Задача сводится к реализации одной функции – получения дерева объектов на дату. Её и создадим, оставив детали для дальнейшего описания.
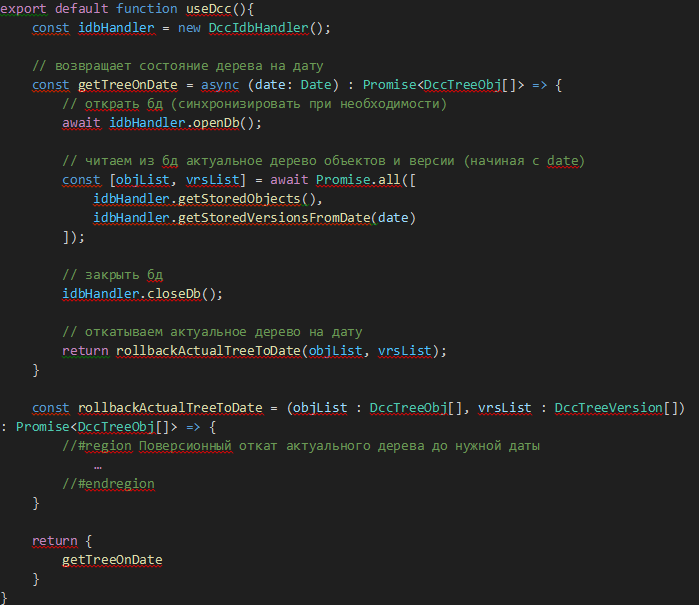
Рис. 5
Итак, чтобы получить нужное нам состояние дерева, необходимо:- Открыть БД.
- Прочитать данные из двух хранилищ (объекты, хранящие актуальное состояние дерева объектов и версии, которые были созданы позже запрашиваемой даты).
- Закрыть БД.
- Откатить текущее состояние дерева до необходимой даты.
Открытие БД
Для того, чтобы открыть БД, нам необходимо узнать, какая версия БД на сервере (запросить последний номер версии в таблице dcc_tree_versions). Это критически важный параметр и, напоминаю, что запрос номера актуальной версии не должен кешироваться браузером (как обсуждалось при подготовке эндпойнта). Далее надо открыть ту же версию клиентской базы. И тут может произойти 4 события:
Открытие БД
Для того, чтобы открыть БД, нам необходимо узнать, какая версия БД на сервере (запросить последний номер версии в таблице dcc_tree_versions). Это критически важный параметр и, напоминаю, что запрос номера актуальной версии не должен кешироваться браузером (как обсуждалось при подготовке эндпойнта). Далее надо открыть ту же версию клиентской базы. И тут может произойти 4 события:
- Onerror. Проблема открытия. Пока нет смысла рассматривать, просто сообщаем о проблеме.
- Onblocked. База заблокирована. Как и в случае onerror, пока только оповещаем об этом.
- Onsuccess. База открылась, версии серверной и клиентской бд совпали, можно читать.
- Onupgradeneeded. Версия на сервере опережает версию на клиенте, и нам необходимо синхронизироваться. Данный пункт подразделяется на два подпункта:
- БД на клиенте ещё нет. Необходимо её создать и записать всё, что есть в серверной БД.
- БД на клиенте создана, но не актуальна. Необходимо догрузить изменения и добавить их БД.
Всем этим управляет базовый хендлер подключения:
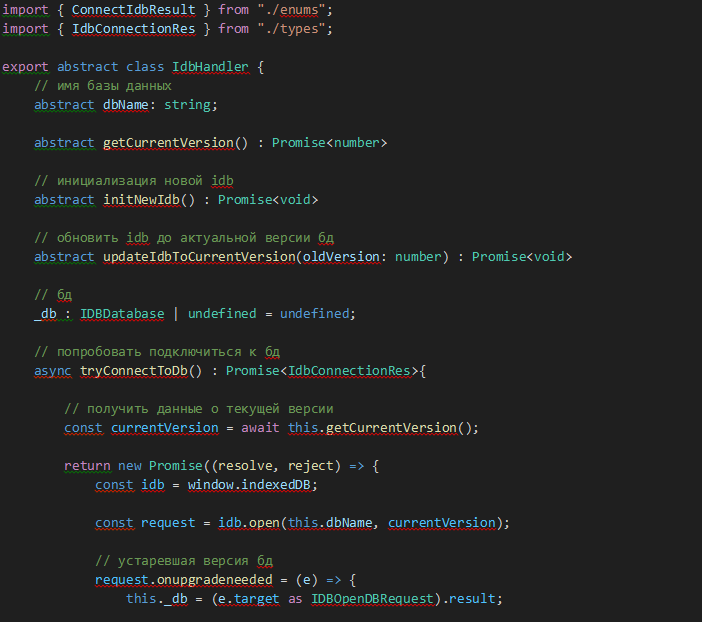
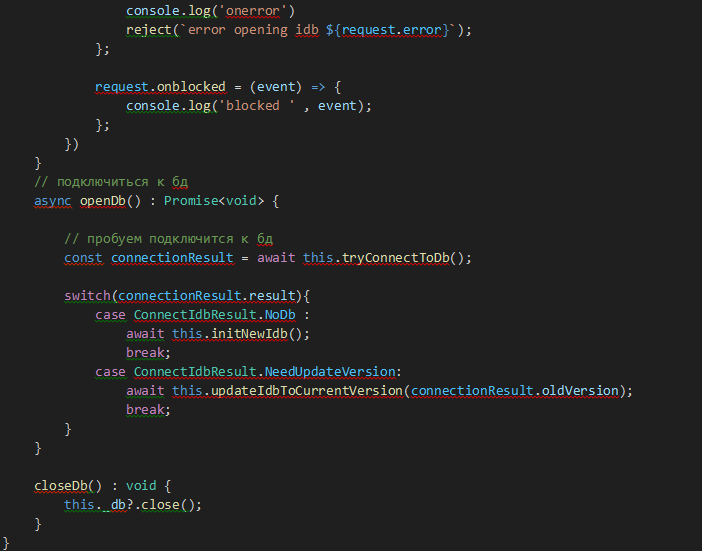
Рис. 6
Теперь перейдём непосредственно к нашей БД и нашей реализации хендлера. Наша БД будет состоять из двух хранилищ:

Рис. 7
Создание БД выглядит следующим образом:
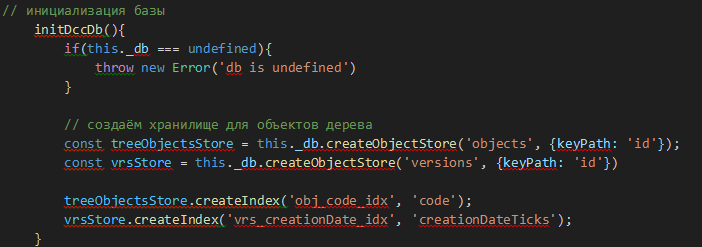
Рис. 8
Полное создание БД выглядит так:
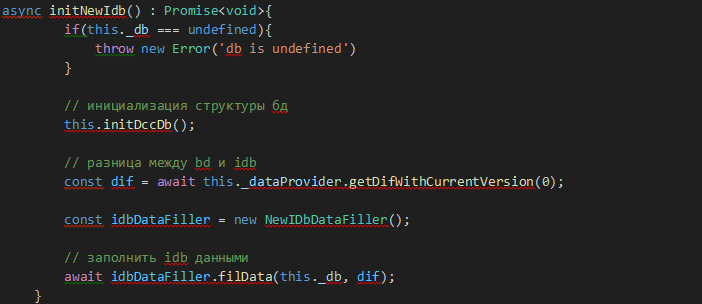
Рис. 9
Несколько комментариев по коду:
_dataProvider – это обёртка над http-клиентом, который взаимодействует с backend-ом. Метод getDifWithCurrentVersion(version: number) сам решает, что необходимо прислать. Версия, равная 0, говорит о том, что мы только создаём БД, и нам необходима вся информация, а вот версия больше 0 запрашивает только необходимые версии и их изменения. Точно такой же метод используется и в случае обновления клиентской БД.
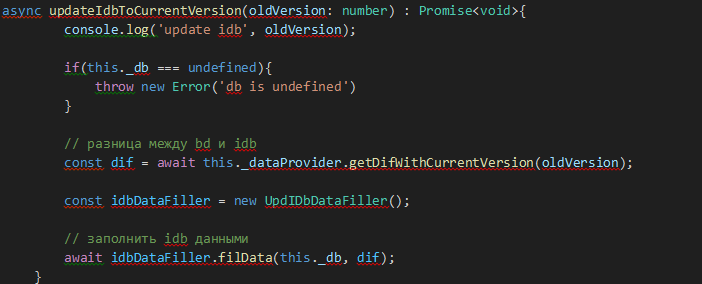
Рис. 10
Классы NewIDbDataFiller и UpdIDbDataFiller нет смысла детально расписывать, т.к их логика довольно проста: NewIDbDataFiller – записывает в хранилище все присланные объекты и версии, UpdIDbDataFiller – обходит версии с изменениями, разбивает изменения по типам и выполняет 4 операции: удаляет объекты (проставляет IsDeleted=true), удаляет связи (зануляет parentId у объект), добавляет объекты, добавляет связи.
Чтение данных
Для чтения данных можно либо открыть курсор, либо воспользоваться методами getAll() у хранилища или индекса. Причем в getAll можно передать дополнительное условие (не так много возможностей как у SQL, но базовые функции есть). Как отмечалось выше, курсор в данной задаче неактуален. На примере функций получения списков объектов и версий проиллюстрируем описанные выше подходы.
Получение объектов из хранилища objects (getAll() без условий для хранилища объектов):
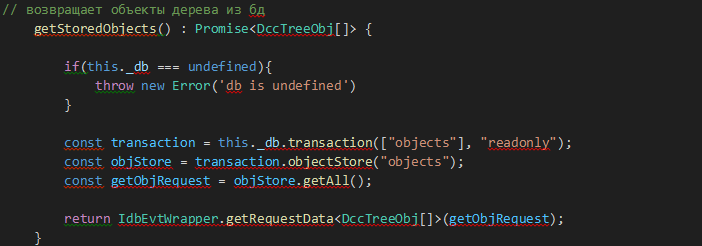
Рис. 11
Получение более свежих версий на дату из хранилища versions (по индексу с условием):
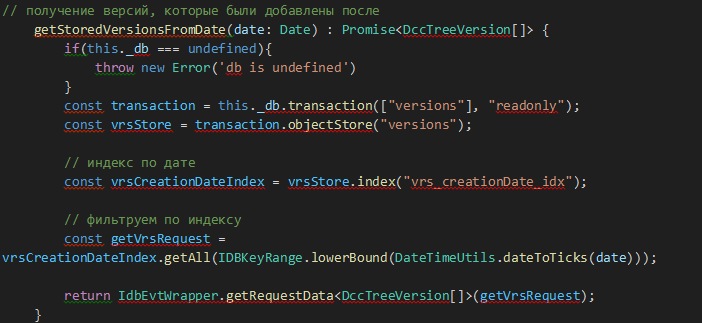
Рис. 12
Теперь наш метод получения состояния дерева на дату готов, описание некоторых методов оставим за скобками, так как они достаточно тривиальны и не отображают суть взаимодействия с IndexedDB. Пробуем запуск. Вызов метода и синхронизация приводит к появлению БД:
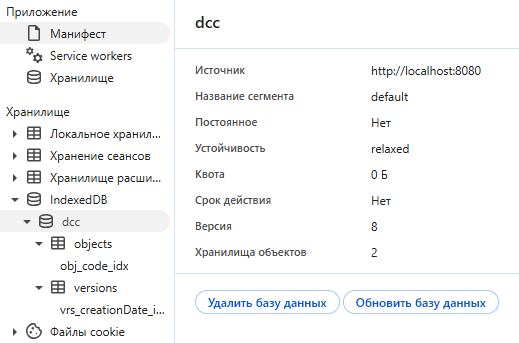
Рис. 12
С необходимыми хранилищами объектов и версий:
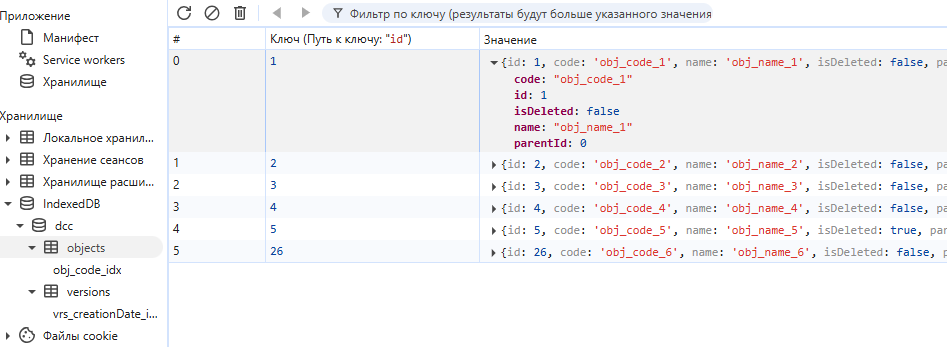
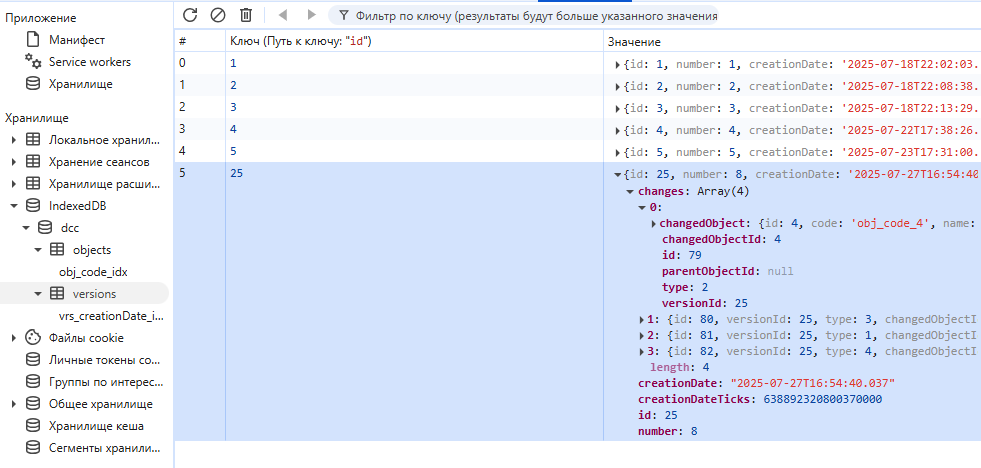
Рис. 13
